A NoSQL (Not Only SQL) database, referring to a “non-SQL” or “non-relational” database, provides a mechanism for storage and extracting of data that is modeled in means other than the tabular relations used in relational databases. NoSQL databases are increasingly used in big data and real-time web applications. NoSQL systems are also often called “Not only SQL” to emphasize that they may support SQL-like query languages, or sit alongside SQL databases in a polyglot persistence architecture.
What Is NoSQL
NoSQL is an approach to database design that can accommodate a wide list of data models, including key-value, document, columnar, and graph formats. NoSQL, which stands for “not only SQL,” is an alternative to traditional relational databases in which data is placed in tables, and data schema is carefully designed before the database is built. NoSQL databases are especially useful for working with large sets of distributed data.
NoSQL includes a wide variety of different database technologies that were developed in response to the demands presented in building modern applications:
Developers are working with applications that create massive volumes of new, rapidly changing data types – structured, semi-structured, unstructured, and polymorphic data.
Long gone is the twelve-to-eighteen-month waterfall development cycle. Now small teams work in agile sprints, iterating quickly and pushing code every week or two, some even multiple times every day.
Applications that once served a finite audience are now delivered as services that must be always-on, accessible from many different devices, and scaled globally to millions of users.
Organizations are now changing to scale-out architectures using open software technologies, commodity servers, and cloud computing instead of large monolithic servers and storage infrastructure.
Relational databases were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the commodity storage and processing power available today.
NoSQL vs. RDBMS
The NoSQL term can be applied to some databases that predated the relational database management system, but it more commonly refers to the databases developed in the early 2000s for the purpose of large-scale database clustering in cloud and web applications. In these applications, requirements for performance and scalability outweighed the need for the immediate, rigid data consistency that the RDBMS ensured for transactional enterprise applications.
Notably, the NoSQL systems were not required to follow an established relational schema. Large-scale web organizations such as Google and Amazon used NoSQL databases to focus on narrow operational goals and employ relational databases as adjuncts where high-grade data consistency is necessary.
Early NoSQL databases for web and cloud applications usually focused on very specific characteristics of data management. The ability to process very large volumes of information and quickly distribute that data across computing clusters were desirable traits in web and cloud design.
NoSQL Database Types
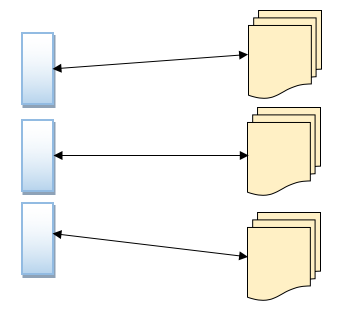
Document databases pair each key with a complex data structure known as a document. Documents can contain many different key-value pairs, key-array pairs, or even nested documents. Document databases, also called document stores, store semi-structured data and descriptions of that data in document format. They allow programmers to create and update programs without needing to reference the master schema. The use of document databases has increased along with the use of JavaScript and the JavaScript Object Notation (JSON), a data interchange format that has gained wide currency among web application programmers, although XML and other data formats can be used as well. Document databases are used for content management and mobile application data handling. Couchbase Server, CouchDB, DocumentDB, MarkLogic, and MongoDB are examples of document databases.
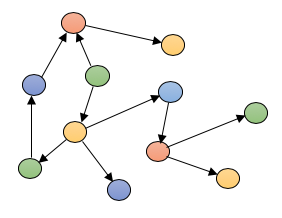
Graph stores are used to store information about networks of data, such as social connections. Graph data stores organize data as nodes, which are like records in a relational database, and edges, which represent connections between nodes. Because the graph system stores the relationship between nodes, it can support richer representations of data relationships. Also, unlike relational models reliant on strict schemes, the graph data model can evolve over time and use. Graph databases are applied in systems that must map relationships, such as reservation systems or customer relationship management. Examples of graph databases include AllegroGraph, IBM Graph, Neo4j and Titan.
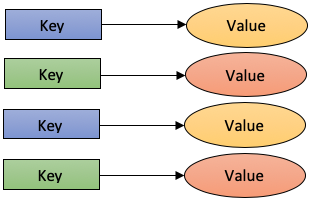
Key-value stores are the simplest NoSQL databases. Every single item in the database is stored as an attribute name (or ‘key’), together with its value. Key-value stores, or key-value databases, implement a simple data model that pairs a unique key with an associated value. Because this model is simple, it can lead to the programming of key-value databases, which are extremely performant and highly scalable for session management and caching in web applications. Implementations differ in the way they are oriented to work with RAM, solid-state drives or disk drives. Examples include Aerospike, Berkeley DB, MemchacheDB, Redis and Riak.
Wide-column stores such as Cassandra and HBase are optimized for queries over large datasets, and store columns of data together, instead of rows. Wide-column stores organize data tables as columns instead of as rows. Wide-column stores can be found both in SQL and NoSQL databases. Wide-column stores can query large data volumes faster than conventional relational databases. A wide-column data store can be used for recommendation engines, catalogs, fraud detection and other types of data processing. Google BigTable, Cassandra and HBase are examples of wide-column stores.
Advantages of NoSQL
When we’re comparing relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several issues that the relational model is not designed to address:
- Large volumes of rapidly changing structured, semi-structured, and unstructured data
- Agile sprints, quick schema iteration, and frequent code pushes
- Object-oriented programming that is easy to use and flexible
- Geographically distributed scale-out architecture instead of expensive, monolithic architecture
Types and examples
There are different ways to classify NoSQL databases, with various categories and subcategories, some of which overlap. What follows is a basic classification by data model, with examples:
| Types | Examples |
|---|---|
|
Column |
Accumulo, Cassandra, Scylla, Apache Druid, HBase, Vertica. |
|
Document |
Apache CouchDB, ArangoDB, BaseX, Clusterpoint, Couchbase, Cosmos DB, IBM Domino, MarkLogic, MongoDB, OrientDB, Qizx, RethinkDB |
|
Key-value |
Aerospike, Apache Ignite, ArangoDB, Berkeley DB, Couchbase, Dynamo, FoundationDB, InfinityDB, MemcacheDB, MUMPS, Oracle NoSQL Database, OrientDB, Redis, Riak, SciDB, SDBM/Flat File dbm, ZooKeeper |
|
Graph |
AllegroGraph, ArangoDB, InfiniteGraph, Apache Graph, MarkLogic, Neo4J, OrientDB, Virtuoso |
NoSQL vs. SQL Summary
| SQL Databases | NoSQL Databases | |
|---|---|---|
|
Types |
One type (SQL database) with minor variations |
Many different types including key-value stores, document databases, wide-column stores, and graph databases |
|
Development History |
Developed in 1970s to deal with first wave of data storage applications |
Developed in late 2000s to deal with limitations of SQL databases, especially scalability, multi-structured data, geo-distribution and agile development sprints |
|
Examples |
MySQL, Postgres, Microsoft SQL Server, Oracle Database |
MongoDB, Cassandra, HBase, Neo4j |
|
Data Storage Model |
Individual records (e.g., ’employees’) are stored as rows in tables, with each column storing a specific piece of data about that record (e.g., ‘manager,’ ‘date hired,’ etc.), much like a spreadsheet. Related data is stored in separate tables, and then joined together when more complex queries are executed. For example, ‘offices’ might be stored in one table, and ’employees’ in another. When a user wants to find the work address of an employee, the database engine joins the ’employee’ and ‘office’ tables together to get all the information necessary. |
Varies based on database type. For example, key-value stores function similarly to SQL databases, but have only two columns (‘key’ and ‘value’), with more complex information sometimes stored as BLOBs within the ‘value’ columns. Document databases do away with the table-and-row model altogether, storing all relevant data together in single ‘document’ in JSON, XML, or another format, which can nest values hierarchically. |
|
Schemas |
Structure and data types are fixed in advance. To store information about a new data item, the entire database must be altered, during which time the database must be taken offline. |
Typically dynamic, with some enforcing data validation rules. Applications can add new fields on the fly, and unlike SQL table rows, dissimilar data can be stored together as necessary. For some databases (e.g., wide-column stores), it is somewhat more challenging to add new fields dynamically. |
|
Scaling |
Vertically, meaning a single server must be made increasingly powerful in order to deal with increased demand. It is possible to spread SQL databases over many servers, but significant additional engineering is generally required, and core relational features such as JOINs, referential integrity and transactions are typically lost. |
Horizontally, meaning that to add capacity, a database administrator can simply add more commodity servers or cloud instances. The database automatically spreads data across servers as necessary. |
|
Development Model |
Mix of open technologies (e.g., Postgres, MySQL) and closed source (e.g., Oracle Database) |
Open technologies |
|
Supports multi-record ACID transactions |
Yes |
Mostly no. MongoDB 4.0 and beyond support multi-document ACID transactions. Learn more |
|
Data Manipulation |
Specific language using Select, Insert, and Update statements, e.g. SELECT fields FROM table WHERE… |
Through object-oriented APIs |
|
Consistency |
Can be configured for strong consistency |
Depends on product. Some provide strong consistency (e.g., MongoDB, with tuneable consistency for reads) whereas others offer eventual consistency (e.g., Cassandra). |

